最近在学校的一个项目中,需要爬取京东的各个商品的评论,然后进行分析。但是看到国内关于Scrapy的资料不是很多,所以就想要把我做的过程写下来。因为自己做的,难以避免一些野路子,希望大大们指出更好的方法。
整体思路:
- 先抓取某一类商品的所有的商品ID,存入Redis
- 从Redis取出商品ID,然后爬取此商品所有评论,存入Mongodb。
分析页面
商品ID列表
打开笔记本电脑的分类:http://list.jd.com/list.html?cat=670,671,672,其中url里面的cat=670,671,672就是商品类别,然后页面上的每一个笔记本电脑都会链接到它自己的详情页面:http://item.jd.com/1592705.html,url中的1466274就是商品ID,打开详情页面以后,确认这个数字就是商品ID了。

所以,想要获取某一类别的所有商品ID,只需要通过商品列表页面,就可以把一页的商品ID取出来。然后,再翻页,直到没有新的商品ID出现。或者通过页面中的最大页数来判断。
找到了数据的位置以后,就是如何把它们提取出来了。
提取数据
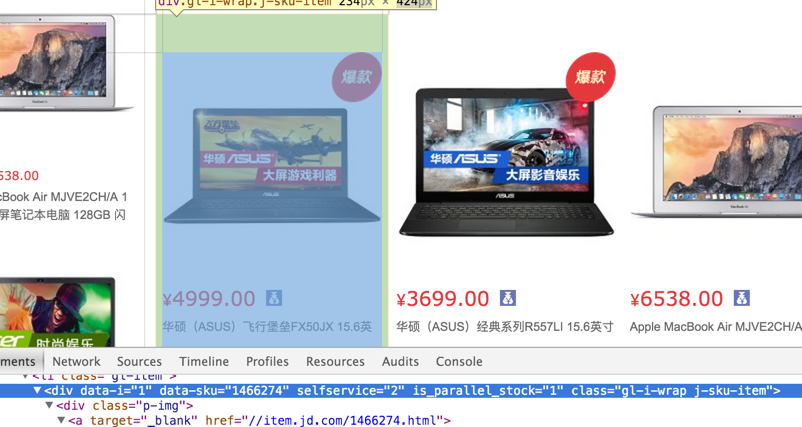
商品的ID,可以看到,是在div下面的data-sku属性`。所以可以通过正则,来把整页的商品ID取出来。
data-sku="(\d+)"
用同样的方法,可以看到最大页数的地方是这样的:
<span class="fp-text"><b>1</b><em>/</em><i>208</i></span>
所以继续用正则(这个地方用XPATH感觉更好),来将其中的208取出来
fp-text.+?<i>(\d+)</i>
某个商品的评论信息
点进一个商品详情,随便选取一段评论,在网页的源码中无法查到,说明评论数据是之后加载的。打开开发者工具中的Network页面,点击下一页的评论,可以看到如下:
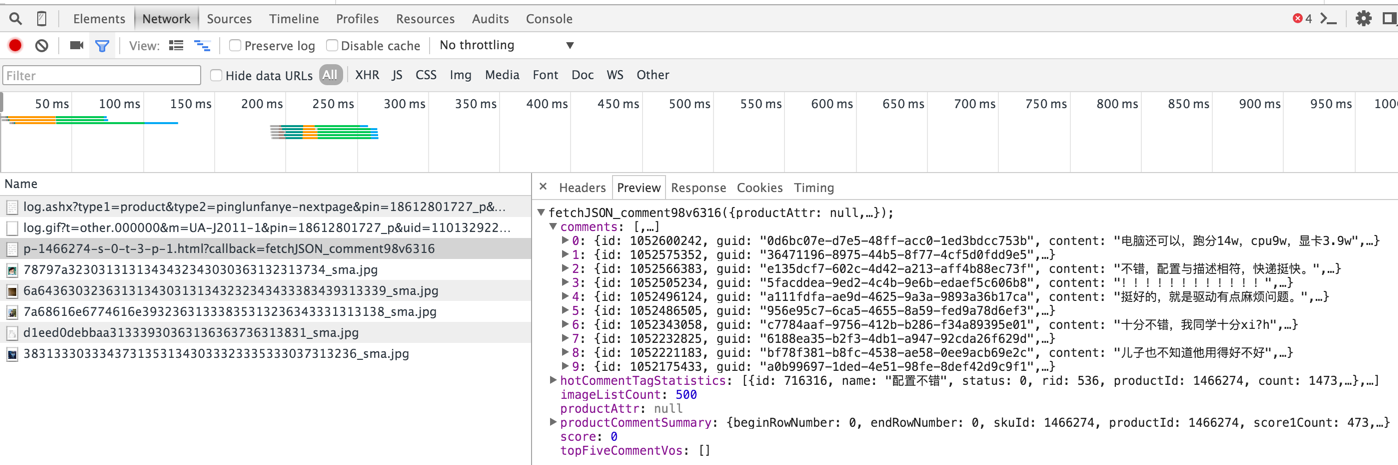
其中被我选中的这个请求,就是获得这个商品评论的方式。也就是:http://s.club.jd.com/productpage/p-[skuid]-s-0-t-0-p-[page].html。