最近在学校的一个项目中,需要爬取京东的各个商品的评论,然后进行分析。但是看到国内关于Scrapy的资料不是很多,所以就想要把我做的过程写下来。因为自己做的,难以避免一些野路子,希望大大们指出更好的方法。
整体思路:
先抓取某一类商品的所有的商品ID,存入Redis
从Redis取出商品ID,然后爬取此商品所有评论,存入Mongodb。
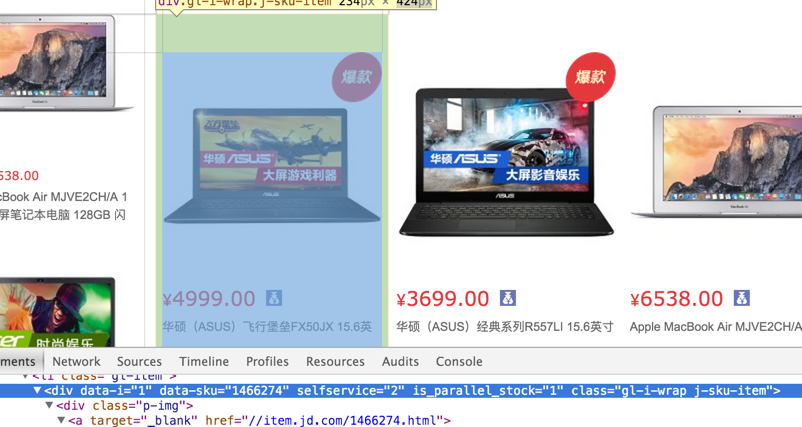
分析页面 商品ID列表 打开笔记本电脑的分类:http://list.jd.com/list.html?cat=670,671,672 ,其中url里面的cat=670,671,672就是商品类别,然后页面上的每一个笔记本电脑都会链接到它自己的详情页面:http://item.jd.com/1592705.html ,url中的1466274就是商品ID,打开详情页面以后,确认这个数字就是商品ID了。
所以,想要获取某一类别的所有商品ID,只需要通过商品列表页面,就可以把一页的商品ID取出来。然后,再翻页,直到没有新的商品ID出现。或者通过页面中的最大页数来判断。
找到了数据的位置以后,就是如何把它们提取出来了。
提取数据 商品的ID,可以看到,是在div下面的data-sku属性`。所以可以通过正则,来把整页的商品ID取出来。
data-sku="(\d+)"
用同样的方法,可以看到最大页数的地方是这样的:
<span class="fp-text"><b>1</b><em>/</em><i>208</i></span>
所以继续用正则(这个地方用XPATH感觉更好),来将其中的208取出来
fp-text.+?<i>(\d+)</i>
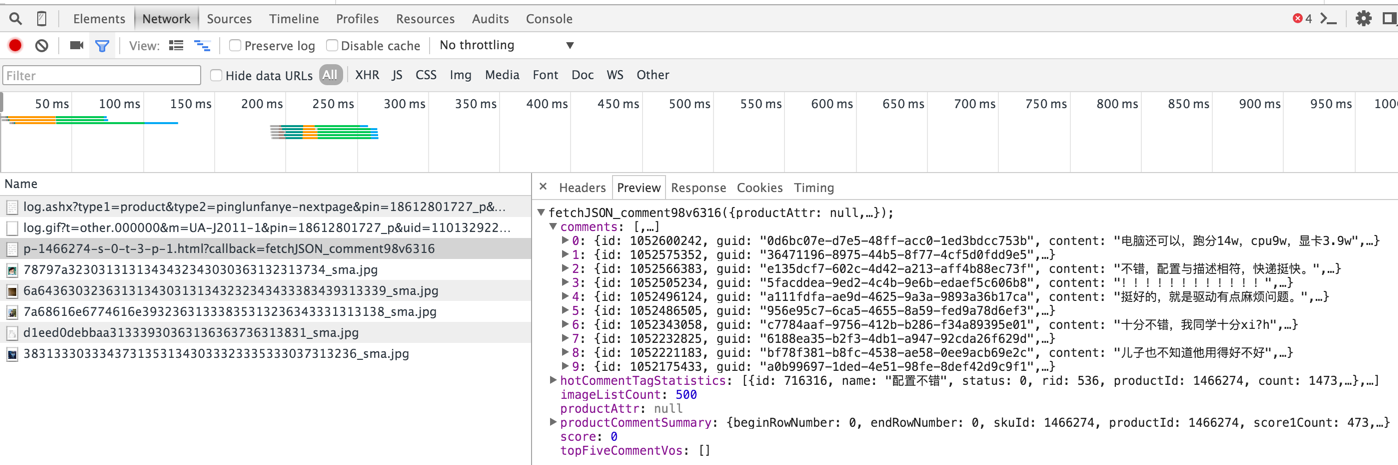
某个商品的评论信息 点进一个商品详情,随便选取一段评论,在网页的源码中无法查到,说明评论数据是之后加载的。打开开发者工具中的Network页面,点击下一页的评论,可以看到如下:
其中被我选中的这个请求,就是获得这个商品评论的方式。也就是:http://s.club.jd.com/productpage/p-[skuid]-s-0-t-0-p-[page].html。
第一次尝试 上述内容中,已经知道了如何获得某一类商品的ID,以及知道如何获得商品的评论数据了。所以,就可以开始最基本的爬虫的编写了。但是编写前,有一个事情需要确定,那就是京东的反爬虫 机制。所以,写了两个简单的脚本,来获取相应的数据。
获取商品列表的代码 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 import reimport requestsbase_url = r'http://list.jd.com/list.html?cat=670,671,672%s' page = r'&page=%d' skuids = set() first_try = requests.get(base_url) sku_re = re.compile(r'data-sku="(\d+)"' , re.MULTILINE | re.IGNORECASE) ids = re.findall(sku_re, first_try.text) print(ids) print('find...' , len(ids)) skuids |= set(ids) i = 2 while True : url = base_url % (page % i) html = requests.get(url) ids = set(re.findall(sku_re, html.text)) if i == 193 or len(ids) == 0 or len(skuids - ids) == 0 : break else : i += 1 skuids |= set(ids) total = len(skuids) print('Total:' , total) with open('skuids.txt' , mode='w' ) as s: for sku in skuids: s.write(sku + '\n' )
这个脚本用了Requests库,使用起来十分方便。因为当时只是简单的测试脚本,所以有的地方写的十分偷懒…整体的思路就是,遍历列表页,通过正则取出此页面的商品ID,放到一个集合中。最后把集合写到一个文件里,方便之后抓取评论数据。
获取商品评论的代码 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 import requestsimport simplejson as json import timeimport randombase_url = r'http://s.club.jd.com/productpage/p-%s-s-0-t-0-p-%d.html' results = open('skuid_comments.json' , mode='a' ) skuid_file = open('skuids.txt' , mode='r' ) user_agents_file = open('uas.txt' , mode='r' ) current_progress = open('progress' , mode='r' ) progress = current_progress.read() current_skuid = None current_page = None if progress: current_skuid = progress.strip().split(' ' )[0 ].strip() current_page = progress.strip().split(' ' )[1 ].strip() ua_list = [x.strip() for x in user_agents_file.readlines()] for skuid_str in skuid_file.readlines(): if current_skuid: if skuid_str.strip() != current_skuid: continue page = int(current_page) current_skuid = None current_page = None else : page = 0 skuid = skuid_str.strip() print('Current Skuid:' , skuid) while True : sec = random.randint(1 , 4 ) time.sleep(sec) ua = random.choice(ua_list) try : comments_json = requests.get(base_url % (skuid, page), headers={'User-Agent' : ua}) print(comments_json.request.headers) except : with open('progress' , mode='w' ) as p: p.write(skuid + ' ' + str(page)) time.sleep(180 ) continue if not comments_json.text: break comments = json.loads(comments_json.text) if len(comments['comments' ]): results.write(comments_json.text + '\n' ) page += 1 print('Page: ' , page) else : break
用上述代码跑了一段时间,发现京东的反爬虫机制还是比较松的,也可能是因为我的频率太慢。然后…基本的测试结束之后,就开始用scrapy了。
使用Scrapy 初始化项目,然后新建两个Spider。项目目录结构如下:
├── jd_comments
│ ├── __init__.py
│ ├── items.py
│ ├── pipelines.py
│ ├── settings.py
│ └── spiders
│ ├── __init__.py
│ ├── comments.py
│ └── skuid_list.py
└── scrapy.cfg └── scrapy.cfg
即创建两个spider:skuid_list和comments。然后,items.py的代码就是这个:
1 2 3 4 5 6 7 8 9 import scrapyclass JdCommentsItem (scrapy.Item) : pass class SkuIdItem (scrapy.Item) : product_id = scrapy.Field()
skuid_list.py 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 import reimport scrapyfrom jd_comments.items import SkuIdItemfrom jd_comments import pipelinesclass SkuidListSpider (scrapy.Spider) : name = "skuid_list" allowed_domains = ["jd.com" ] base_url = 'http://list.jd.com/list.html?cat=%s' page = '&page=%d' p = re.compile(ur'fp-text.+?<i>(\d+)</i>' , re.MULTILINE | re.IGNORECASE) sku_re = re.compile(r'data-sku="(\d+)"' , re.MULTILINE | re.IGNORECASE) def __init__ (self, cid='670,671,672' , *args, **kwargs) : super(SkuidListSpider, self).__init__(*args, **kwargs) self.cid = cid self.start_urls = [] self.max_page = None def start_requests (self) : print('Into start requests...' ) return [scrapy.Request(self.base_url % self.cid, callback=self.get_max_pages)] def get_max_pages (self, response) : self.logger.info('get max pages: %s. CID: %s' , response.url, self.cid) self.max_page = int(self.p.search(response.body).group(1 )) yield scrapy.Request(response.url, callback=self.parse) for i in range(1 , self.max_page + 1 ): yield scrapy.Request(response.url + (self.page % i)) def parse (self, response) : self.logger.info('get page: %s' , response.url) id_list = self.sku_re.findall(response.body) for skuid in id_list: yield SkuIdItem(product_id=skuid)
现在的商品ID爬虫,只能够把ID输出来,就没有然后了…所以需要使用pipeline把找到的这些商品ID都放入redis中。但是,一般情况下,pipeline都是针对所有爬虫的。而对于商品ID需要存入Redis,而商品评论只需要存入Mongodb里面。所以,还需要一个用来检测不同爬虫执行不同pipeline的函数。
pipelines.py 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 import functoolsimport redisfrom jd_comments import redis_poolr = redis.Redis(connection_pool=redis_pool) def check_spider_pipeline (process_item_method) : @functools.wraps(process_item_method) def wrapper (self, item, spider) : msg = '%%s %s pipeline step' % (self.__class__.__name__,) if self.__class__ in spider.pipeline: spider.logger.debug(msg % 'executing' ) return process_item_method(self, item, spider) else : spider.logger.debug(msg % 'skipping' ) return item return wrapper class SkuidRedisPipeline (object) : @check_spider_pipeline def process_item (self, item, spider) : r.sadd('comments:queue' , item['product_id' ]) return item
有了这个代码以后,为了应用这个pipeline,需要在settings.py里面设置。并且,在刚才的skuid_list.py中加入如下代码:
1 2 3 4 5 6 .... sku_re = re.compile(r'data-sku="(\d+)"' , re.MULTILINE | re.IGNORECASE) pipeline = set([pipelines.SkuidRedisPipeline]) def __init__ (self, cid='670,671,672' , *args, **kwargs) :....
(转载请注明出处)